架构
一、物理结构¶
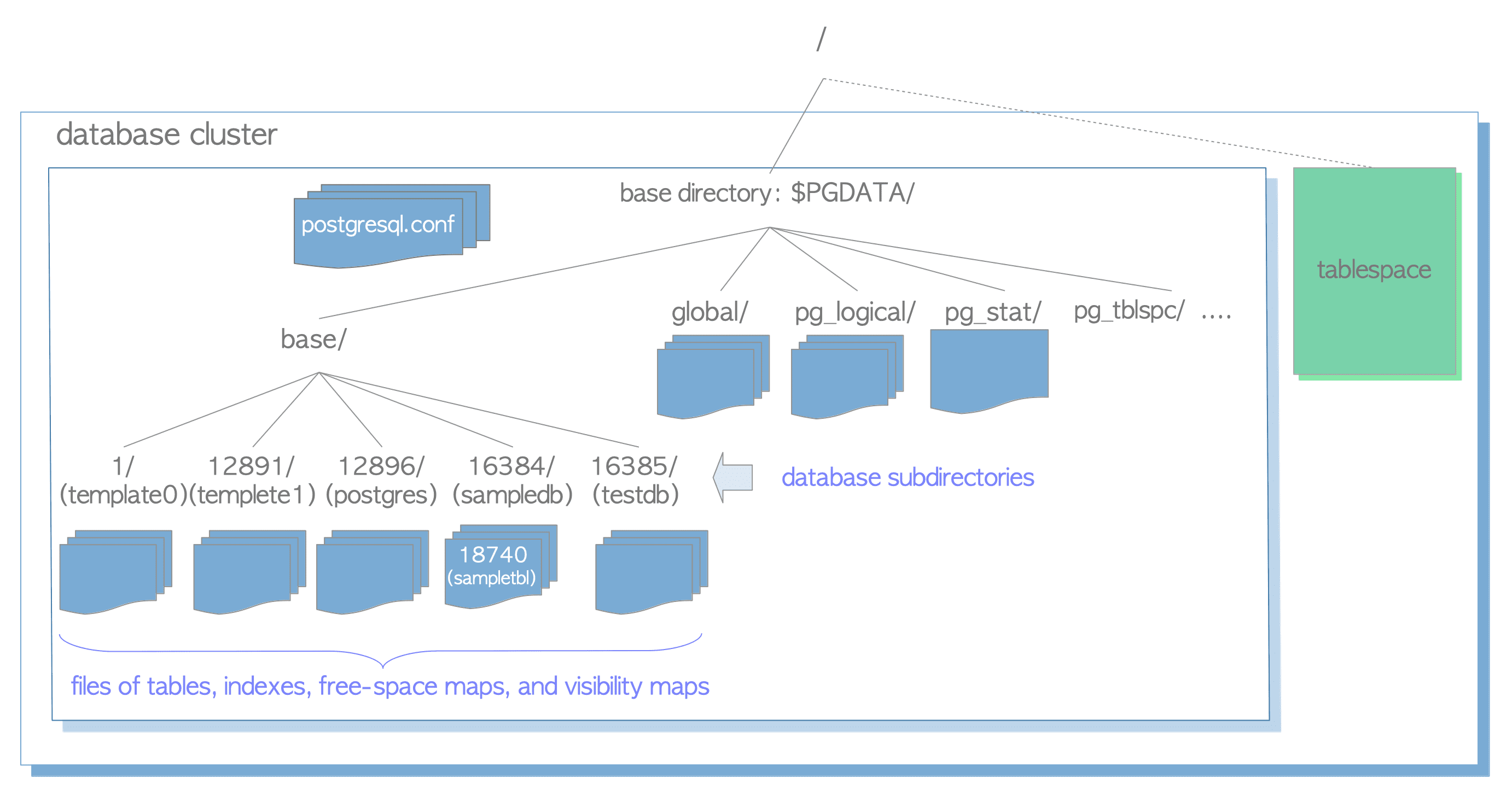
$PGDATA目录结构
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | |
1. 数据库结构¶
一个数据库与base子目录下的一个子目录对应,且该子目录的名称与相应数据库的oid相同。例如,当数据库postgres的oid为13593时,它对应的子目录名称就是13593。
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
2. 表和索引结构¶
在数据库内部,表和索引作为数据库对象是通过oid来管理的,而这些数据文件由变量relfilenode管理。表和索引的relfilenode值通常与其oid一致。
1 2 3 4 5 6 7 | |
表和索引的relfilenode值会被一些命令(例如TRUNCATE、REINDEX、CLUSTER)所改变。例如对表tbl执行TRUNCATE命令,PostgreSQL会为表分配一个新的relfilenode(16387),删除旧的数据文件(16384),并创建一个新的数据文件(16387)。
1 2 3 4 5 6 7 | |
使用函数pg_relation_filepath能够根据oid或名称返回关系对应的文件路径。
1 2 3 4 5 | |
当表和索引的文件大小超过1GB时,PostgreSQL会创建并使用一个名为relfilenode.1的新文件。如果新文件也填满了,则会创建下一个名为relfilenode.2的新文件,以此类推。
3. 表空间¶
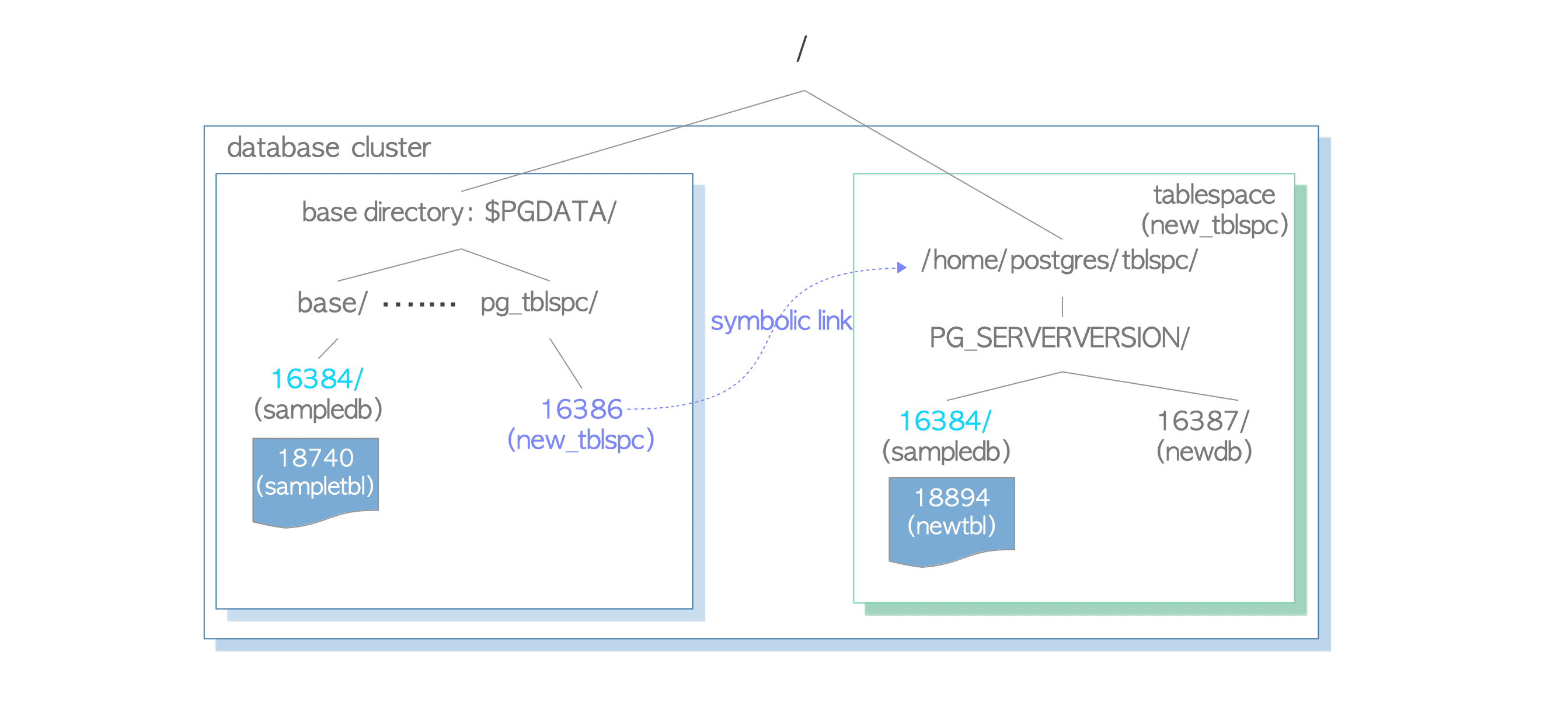
- PostgresQL中的表空间是基本目录之外的附加数据区域
- 初始化数据库后默认的表空间pg_default、pg_global
- pg_global表空间的物理文件位置在数据目录的global目录中,它用来保存系统表。
- pg_default表空间的物理文件位置在数据目录的base子目录中,是templateo和template1数据库的默认表空间。
- 创建数据库时,默认从template1数据库进行克隆,因此除非特别指定了新建数据库的表空间,否则默认使用template1使用的表空间,即pg_default表空间。
执行CREATE TABLESPACE语句会在指定的目录下创建表空间。在该目录下还会创建版本特定的子目录。版本特定的命名方式为:PG_'Major version'_'Catalogue version number'
1 2 3 4 5 6 7 8 9 10 | |
表空间目录通过pg_tblspc子目录中的符号链接寻址,链接名称与表空间的oid值相同。
1 2 3 4 5 6 7 8 9 10 | |
3.1 表空间下创建新库¶
如果在该表空间下创建新的数据库(oid为16387),则会在版本特定的子目录下创建相应的目录。
1 2 3 4 5 6 7 8 | |
3.3 表空间下创建新表¶
如果在该表空间内创建一个新表,但新表所属的数据库却创建在基础目录下,那么 PG 会首先在版本特定的子目录下创建名称与现有数据库oid相同的新目录,然后将新表文件放置在刚创建的目录下。
1 2 3 4 5 6 | |
二、进程结构¶
1 2 3 4 5 6 7 8 9 10 11 | |
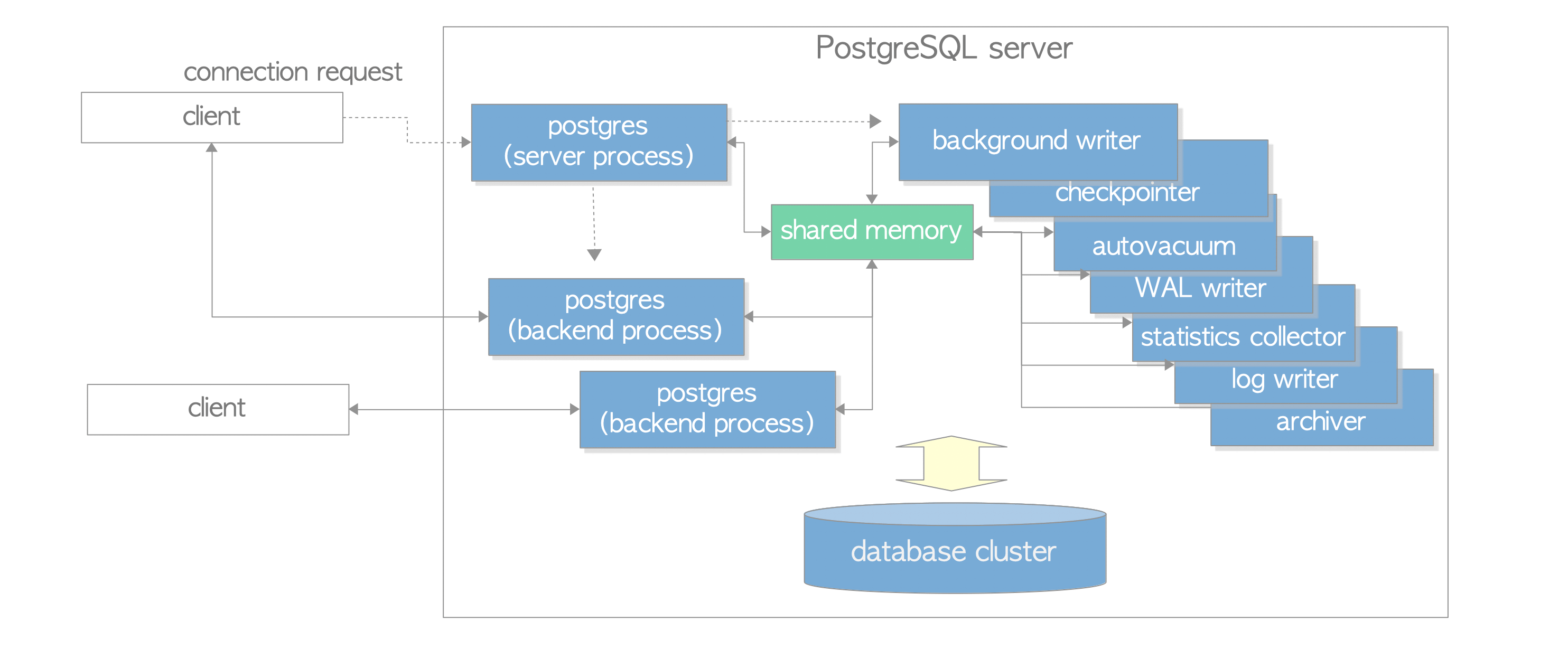
采用多进程架构,包含下列进程:
- Postgres服务器进程(postgres server process)是所有数据库集簇管理进程的父进程。
- 每个后端进程(backend process)负责处理客户端发出的查询和语句。
- 各种后台进程(background process)负责执行各种数据库管理任务(例如清理过程与存档过程)。
- 各种复制相关进程(replication associated process)负责流复制。
- 后台工作进程(background worker process)在9.3版本中被引入,它能执行任意由用户实现的处理逻辑。
1. Postgres服务器进程¶
- postgres服务器进程是PostgreSQL服务器中所有进程的父进程,在早期版本中被称为“postmaster”。
- 执行pg_ctl启动一个postgres服务器进程。它会在内存中分配共享内存区域。
- 一个postgres服务器进程只会监听一个网络端口,默认端口为5432。
2. 后端进程¶
-
每个后端进程(也称为“postgres”)由 postgres 服务器进程启动,并处理连接另一侧的客户端发出的所有查询。
-
PostgreSQL允许多个客户端同时连接,配置参数max_connections用于控制最大客户端连接数(默认为100)。
3. 后台进程¶
| 进程 | 描述 |
|---|---|
| background writer | 本进程负责将共享缓冲池中的脏页逐渐刷入持久化存储中(例如,HDD、SSD) |
| checkpointer | 在9.2及更高版本中,该进程负责处理检查点 |
| autovacuum launcher | 周期性地启动自动清理工作进程,更准确地说,它向postgres服务器请求创建白动清理工作进程 |
| WAL writer | 本进程周期性地将WAL缓冲区中的WAL数据刷入持久存储中 |
| statistics collector | 本进程负责收集统计信息,用于诸如pg_stat_activity、pg_stat_database等系统视图 |
| logging collector (logger) | 本进程负责将错误消息写入日志文件 |
| archiver | 本进程负责将日志归档 |
三、逻辑结构¶
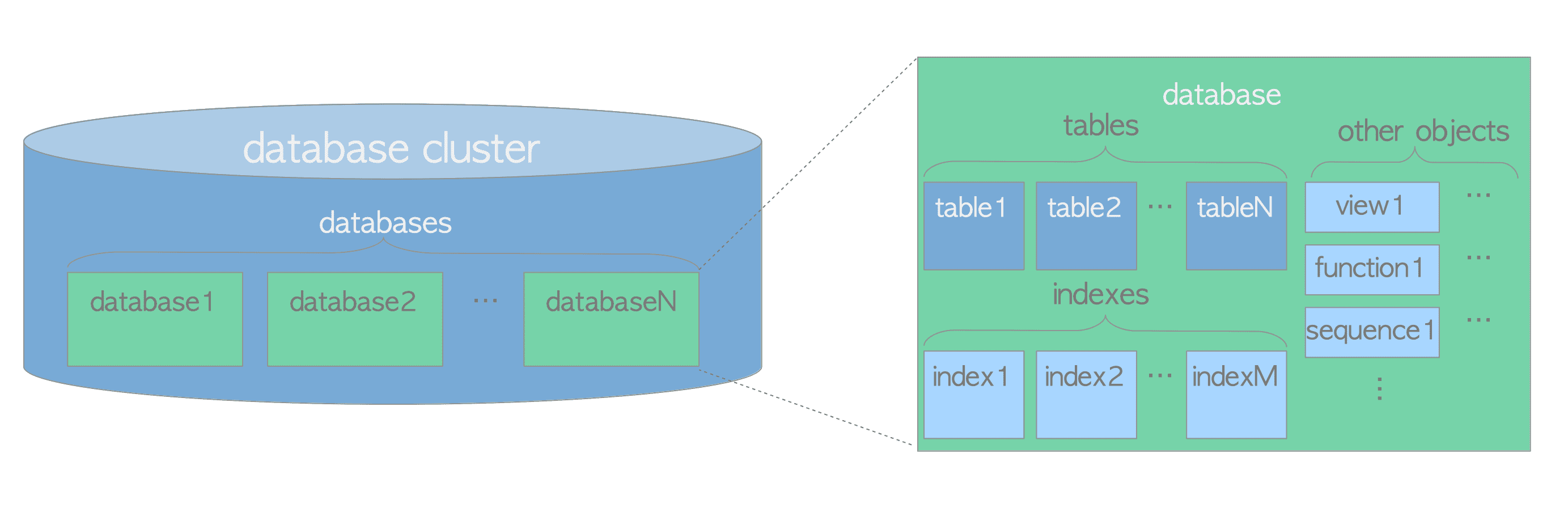
Postgres数据库集群是由PostgreSQL服务器管理的数据库的集合。PostgresQL中的“数据库集”一词并不意味着“一组数据库服务器”。PostgreSQL服务器在单个主机上运行,并管理单个数据库群集。 数据库是数据库对象的集合。在关系数据库理论中,数据库对象是用来存储或引用数据的数据结构。堆(heap)表是一个典型的例子,它有很多类似于索引、序列、图、函数等等。在PostgresQL中,数据库本身也是数据库对象,在逻辑上彼此分离。
四、内存结构¶
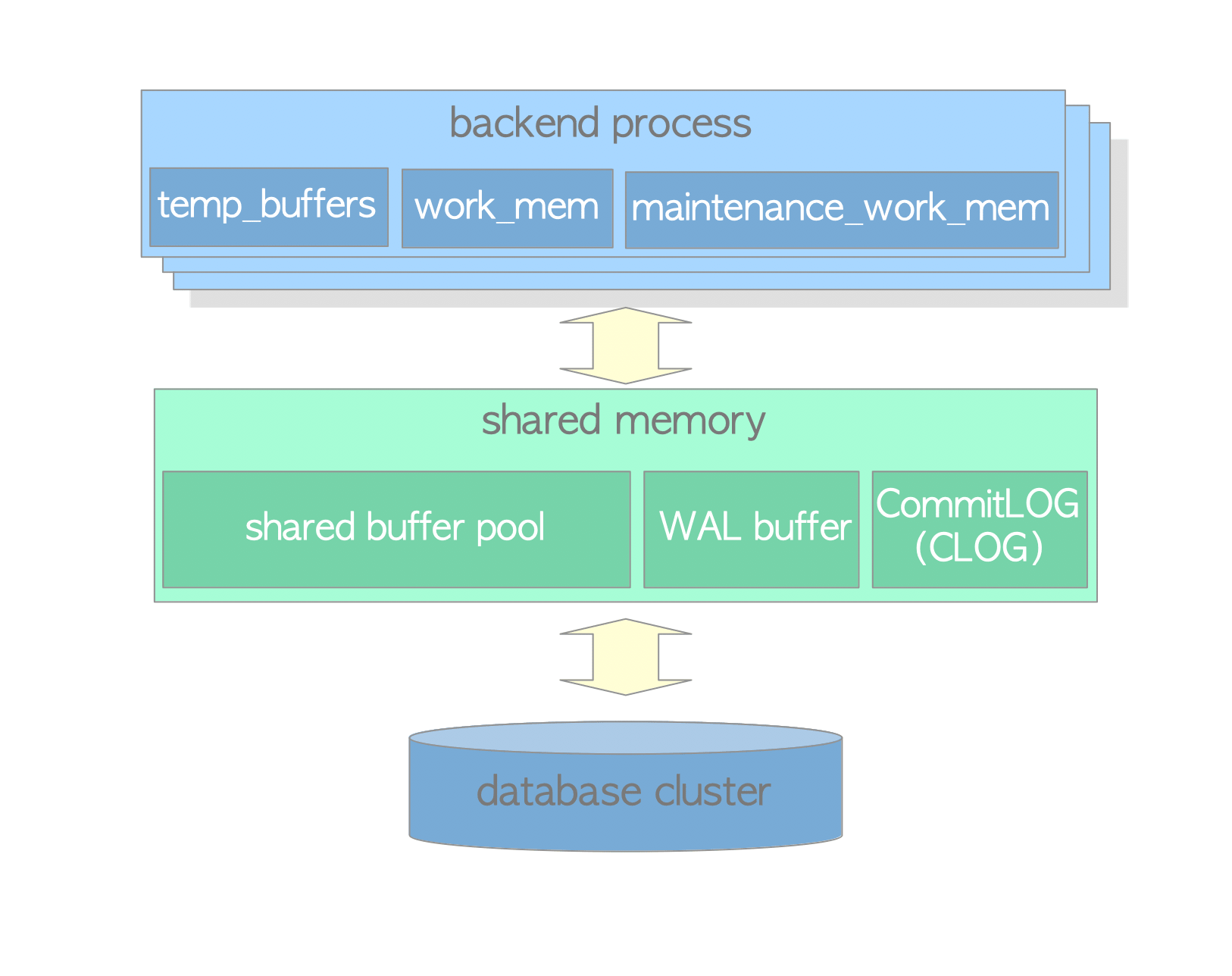
PostgreSQL的内存架构可以分为两个部分:
- 本地内存区域——由每个后端进程分配,供自己使用,用于查询处理。
- 共享内存区域——供PostgreSQL服务器的所有进程使用。
1. 本地内存区¶
| 子区域 | 描述 |
|---|---|
| work_mem | 执行器在执行ORDER BY和DISTINCT时使用该区域对元组做排序,以及存储归并连接和散列连接中的连接表 |
| maintenance_work mem | 某些类型的维护操作使用该区域(例如VACUUM、REINDEX) |
| temp_buffers | 执行器使用此区域存储临时表 |
2. 共享内存区¶
| 子区域 | 描述 |
|---|---|
| shared buffer pool | PostgreSQL将表和索引中的页面从持久存储加载至此,并直接操作它们 |
| WAL buffer | 为确保服务故障不会导致任何数据丢失,PostgreSQL实现了WAL机制。WAL数据(也称为XLOG记录)是PostgreSQL中的事务日志:WAL缓冲区是WAL数据在写入持久存储之前的缓冲区 |
| commit log | 提交日志(CommitLog,CLOG)为并发控制(CC)机制保存了所需的所有事务状态(例如进行中、已提交、已中止等) |
除了上面这些,PostgreSQL还分配了以下几个区域:
- 用于访问控制机制的子区域(例如信号量、轻量级锁、共享和排他锁等)。
- 各种后台进程使用的子区域,例如checkpointer和autovacuum。
- 用于事务处理的子区域,例如保存点与两阶段提交(2PC)。