Checkpoint
检查点¶
1. checkpoint进程¶
checkpoint进程的作用:
- 为数据恢复做准备工作
- 共享缓冲池上脏页的刷盘
1.1 数据库恢复时checkpoint流程¶
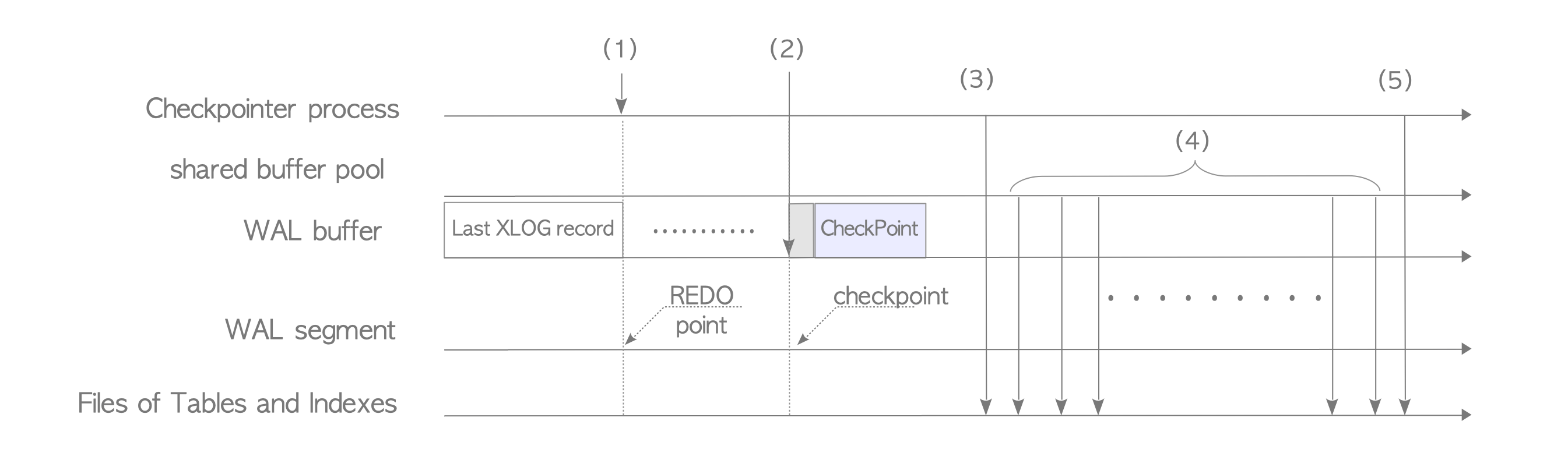
- 当checkpoint进程启动时,会将REDO点存储在内存中,REDO点是上次检查点开始时刻XLOG记录的写入位置,也是数据库恢复的开始位置。
- 该检查点相应的XLOG记录(即检查点记录)会被写入WAL缓冲区,该记录的数据部分是由CheckPoint结构体定义的,包含了一些变量,如步骤(1)中REDO点的位置。另外,写入检查点记录的位置,也按照字面意义叫作checkpoint。
- 共享内存中的所有数据(例如,CLOG的内容)都会被刷入持久化存储中。
- 共享缓冲池中的所有脏页都会被逐渐刷写到存储中。
- 更新pg_control文件,该文件包含了一些基础信息,如上一次检查点的位置。
checkpoint进程会创建包含REDO点的检查点,并将检查点位置与其他信息存储到pg_control文件中。因此,PostgreSQL 能够通过从REDO点回放WAL数据来进行恢复(REDO点是从检查点中获取的).
2. 触发checkpoint进程执行Checkpoint的情况¶
- 达到自上一个检查点到参数checkpoint_timeout配置的时间间隔,默认的时间间隔为300s(5min)。
- 在9.4及更低版本中,自上一次检查点以来消耗的 WAL 段文件超出了参数checkpoint_segments设置的数量(默认值为3)。
- 在9.5及更高版本中,pg_xlog(10.0版本之后是pg_wal)中的WAL段文件总大小超过参数max_wal_size设置的值(默认值为1GB,64个段文件)。
- PostgreSQL服务器以smart或fast模式关闭。
- 当超级用户手动执行CHECKPOINT命令时,该进程也会启动。
3. 检查点的作用¶
所有的数据库几乎都有检查点机制,为什么需要检查点呢,有以下几个作用: 1. 定期保存修改过的数据块(保护劳动果实)。检查点发生时,检查点进程会把共享缓冲区中的脏块(被修改过的块)写入磁盘,永久保存,否则如果发生主机断电等故障,内存中的数据块就会去失,该检查点的发生频率由checkpoint_timeout控制,定期发生。 2. 做为实例恢复时起始位置,如果发生实例崩溃,那么下一次启动时则需要进行实恢复,数据库根据最近一次检查点的位置做为起始位置开始recovery 3. 做为介质恢复时起始位置,每次进行物理各份时都会发生一个检查点,用来判断将来进行恢复时的起始位置,因为各份时数据文件是有先后顺序,备份出来的数据文件是不一致的,将来恢复出来后需要应用归档日志把他们变成同步,开始各份的位置就是将来recovery的位置。
4. 检查点调整¶
- 检查点发生的间隔时间决定了实例恢复需要的时长, checkpoint_timeout设置的值应该根据业务的需求设置,以实例崩时,下一次打开数据库时长的容忍度而设置。
- 间隔时间短,则实例恢复需要的时间就短,可提高数据库的可用性,但是会增加IO操作,降低数据库状态性能,检查点发生时属于密集型O操作,会占用大量系统资源。
- 间隔时间长,则实例恢复需要的时间就长,会降低数据库的可用性,但是会减少V/0操作,提高数据库状态性能
checkpoint completion_target数据库中一个至关重要的参数,主要与参数checkpoint_timeout配合使用,值越小意味着检查点要越快完成,要求写得要快。
控制每次检查点发生时io的吞吐量,值越高,则i/o占用的资源越少,数据库性能越好:值越低,则io占用的资源越多,影响数据库性能,但是提高检查点完成速度。
| checkpoint_completion_target | checkpoint timeout (min) | 每次检查点需要写入的数据(GB) | 磁盘i/o速度/秒 (GB) | 实际写入速度(MB) |
|---|---|---|---|---|
| 0.5 | 5 | 100 | 1 | 670 |
| 0.9 | 5 | 100 | · | 380 |
实际数据写入速度=100/(0.9*5*60*1024)≈380M/s